
首页 > 深度 Google:把Prompt再说一遍,准确率暴涨76%
Google:把Prompt再说一遍,准确率暴涨76%
Google:把Prompt再说一遍,准确率暴涨76%
本文来自微信公众号: 叶小钗 ,作者:叶小钗
见的公司多了后,我不得不承认一个事情:很多人不会写提示词,而在提示词写得稀碎的情况下,你想要模型表现很好,那是不可能的。并且在越是复杂的情况下,提示词越难写,有个说法很贴切:
LLM将之前代码中复杂的逻辑转移到提示词了,复杂度没有消失,他只是转移了
在复杂的提示工程世界里,为了提高大模型的表现,我们发明了各种“秘技”,从CoT到角色扮演再到少样本示例等,他们都能很好的工作。
但最近Google Research的一项新研究却表明:也许我们想得太复杂了:
有时候,只需把问题重复一遍就能让模型变聪明
Prompt Repetition Improves Non-Reasoning LLMs》
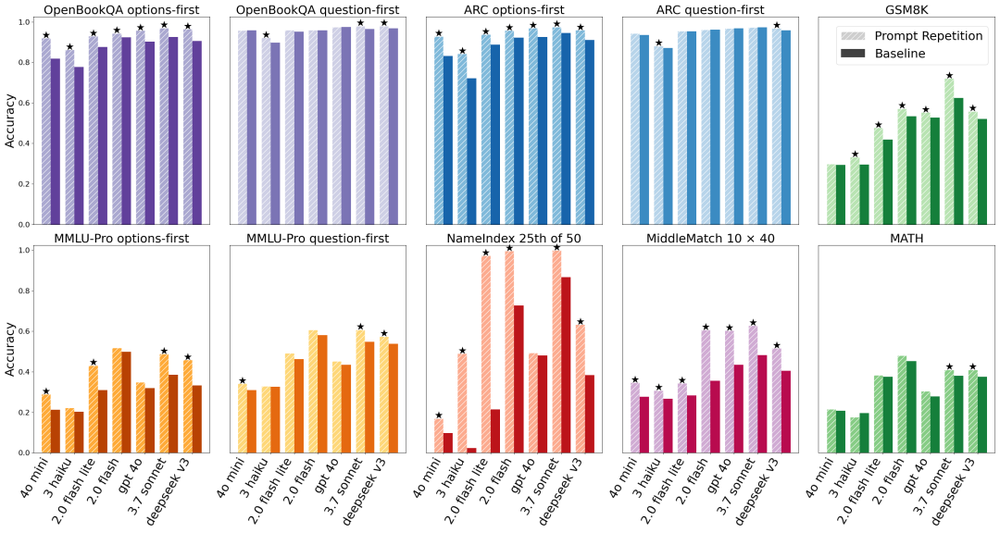
这听起来匪夷所思,但数据说明一切:在不使用链式推理的任务中,仅靠复制+粘贴地重复提示词,某些模型的准确率竟从21%飙升至97%,提升幅度高达76个百分点,这个世界可太疯狂了...
并且,在研究者测试的70组模型与任务对比中,这个土味技巧取得了47胜0负的战绩,没有一次表现下降。
如此惊人的结果,不禁让人怀疑:“就说两遍”居然成了正儿八经的优化策略,这背后有什么原理?今天我们就来为你揭开这一技巧的神奇面纱,并扩展讨论提示词在现代大模型中的作用和实用方法。
unsetunset提示词技巧unsetunset
在不侵入模型的情况下,提示词是我们与模型唯一的交互方式,我们输入的一段话、一个问题或一条指令,就是提示词(prompt):
你可以把提示词理解为给模型下达的“任务说明”:它定义了我们希望模型做什么。这种特性是指令微调带来的结果,模型学会对各种形式的提示做出顺从的回应。
设计不同的提示词,来引导模型的行为
。不同的任务类型对提示词有不同的要求,比如要求模型回答问题、生成创意故事,还是遵循特定格式、语气风格,不同类型提示词的效果会有所不同:
以上是我们在生产中一定会接触到的提示词技巧,然而,Google的新发现提醒我们:有时最简单直接的提示修改,可能带来出乎意料的效果。
unsetunset神奇的提示词重复unsetunset
在探讨“提示词重复”这一奇技之前,我们需要了解模型一个先天局限。当前主流的LLM大多是因果语言模型,意思是它们以从左到右的顺序处理文本;
当模型在读输入提示时,每处理下一个词,只能“看到”它左边已经出现的内容,对右边尚未出现的词一无所知。
也就是说,模型读提示是单向的,先后的信息顺序会严重影响它对任务的理解。
举个例子,如果我们的提示是:
<背景信息><问题>
模型阅读时会先看到背景再看到问题;而如果提示顺序反过来:
<问题><背景信息>
那么当模型读到问题时,并不知道后面还有背景补充,可能倾向于直接回答。
等它读完提示里的背景,可能已经生成了一部分回答,造成前后不一致。这种因为注意力单向导致的信息利用不充分,被研究者形象地称为“因果盲点”。
对于简单任务,顺序影响可能还小;但在复杂提示场景中(比如长背景+问题;或选项在、前题目在后的选择题),提示信息的排列就成了影响模型表现的关键因素。
我们在提示工程中就需要斟酌了:是先提供背景知识,再问问题?还是先提问再给出补充信息?不同排列可能导致输出质量天差地别。这都是因为因果模型看不到未来词,只能顺序地利用提示。
从这里就可以看出来了,这其实是架构缺陷带来的理解问题
理解了这一点,你可能已经猜到“提示词重复”要解决的正是这个因果盲点问题。没错,这个简单粗暴的技巧本质上就是为了弥补单向注意力的不足。那么它究竟怎么做到的呢?
unsetunset提示词重复揭秘unsetunset
研究者提出的提示词重复(Prompt Repetition),其实非常容易描述:把输入的整段提示词重复一次,然后提交给模型。形式化地说,就是将原输入从
“<QUERY>”→“<QUERY><QUERY>”
也就是说,如果你本来打算问模型一个问题,现在就把同样的问题再粘贴一遍,一并发送。
就这样“傻逼”的行为,在不需要模型进行CoT的情况下,带来了显著性能提升。许多网友看到论文结论时和我的反应一样:
这也太离谱/离谱了吧,这么蠢的方法居然这么好使!
然而仔细想想,它背后的原理很有意思:
他给予了模型“回头看”的机会:当提示被重复两遍时,模型在处理第二遍提示内容时,相当于已经“读过”第一遍提示。
这意味着第二遍提示的每个token(词元)都可以通过注意力机制看到第一遍提示中的所有内容。
形象地说,模型第一次读提示或许一知半解,但当它第二次再读时,就好像拥有了“上帝视角”,可以参考之前完整的信息来更准确地理解问题。这有效弥补了因果盲点:第二遍阅读为模型提供了类似双向注意力的效果。
从成都到北京有多少可以自驾游的景点?
应用提示词重复后,我们则在一次请求中问它两遍:
从成都到北京有多少可以自驾游的景点?从成都到北京有多少可以自驾游的景点?
模型处理第二遍问题时,实际上已经看过了完整的问题一次,因此更有可能回忆起相关细节或提高准确率。这个过程并不需要我们提供任何新的信息,仅仅是重复关键信息以强化模型的注意。
当然,重复提示主要针对不要求模型输出详细推理过程的场景
对于那些本就需要逐步推导、一步步解释的任务,我们通常会使用CoT这类技巧,而不会希望模型只给直接答案。
unsetunset单向理解→自我辩驳unsetunset
改善模型对信息的接收与理解,解决“因果盲点”问题
输入被充分理解,模型一次性生成的答案也未必可靠。
,但是与模型交互的复杂性不止于此,因为很多时候就算
这就是提示工程中另一个关键维度需要被关注:如何引导模型进行更深入、更严谨的自我审查,从而显著提升答案的准确性与鲁棒性。
在这方面,“角色反转提示”是我用下来觉得效果还不错的技巧。
当前主流大模型被训练为一次性生成流畅、自信的回答,这种模式存在一个固有缺陷:模型倾向于沿着统计上最可能的路径生成连贯答案,而不会主动暂停并质疑自己的推理过程、验证假设或审视边界情况。
其结果常常是,一个表面上逻辑完备、表述清晰的回答,可能隐藏着不易察觉的逻辑漏洞、或未经处理的异常场景。这个时候自我辩驳提示词就出现了:
角色反转提示的操作极为简单:
在模型给出初始答案后,要求它转换身份,从一个“辩护者”变为一个“批判者”。这跟我们之前的六顶思考帽提示词模式很类似
具体而言,就是指示模型以对手的视角,专门针对自己刚才的答案进行质疑和攻击,这个过程激活了模型内部被压制的“对抗性思维”模式。
当任务目标从“生成一个答案”转变为“找出这个答案的弱点”时,模型会调用不同的知识关联与推理路径,从而更有可能:
基于这些自我批评,我们可以要求模型修订其初始答案,从而整合反馈,产出一个更加周密、可靠的结果。
这里大家也看出来了,所有类似这种多轮审视的逻辑,都是Token换稳定的策略
我实际测试下来有一定效果,更合适的说法可能是:对于有效果的有效果,对于没效果的一直没效果...
这里大家可能不太理解,现在有道数学题,你因为粗心大意做错了,所以在提示下你一定能作对,但是这道题你就是不会,那么你怎么都不会
接下来给出之前的简单案例:
六顶思考帽是一种经典的“平行思维”框架,旨在将混乱的思考过程结构化。其核心是赋予思考者六种不同的角色“帽子”:白帽:客观中立,只关注事实与数据。红帽:感性直觉,表达情绪与预感。黑帽:谨慎批判,专注风险与缺陷。黄帽:积极乐观,看到价值与机会。绿帽:创新创造,探索新想法与可能性。蓝帽:统筹控制,管理思考流程与总结。其威力在于强制切换视角,避免人们被单一立场(比如一味批判或盲目乐观)所困,从而实现对问题的全方位审视。举个具体的案例,要不要在公司上马一个Agent项目,跑一轮六顶思考帽,大致会变成这样一套ReAct循环:白帽:我到底知道哪些事实?现在公司有什么基础?预算多少?有哪些现成数据和系统?黑帽:最坏的情况是什么?可能踩哪些坑?哪些部门一定会强烈反对?黄帽:如果成功了,最大的收益是什么?对业务、对团队能力有哪些放大?绿帽:在现有资源约束下,有没有一些性价比更高的落地路线?比如先从一个小流程改造,而不是一上来做全栈Agent平台。蓝帽:把前面所有视角收束成一个可执行的行动计划,先做什么,怎么拆阶段,怎么验证,失败后怎么止损,蓝猫开始收尾做输出了。这一整套六顶思考帽跑下来,模型在不断地对自己刚刚的想法进行追问、纠偏和补充,这就是典型的模型自问自答,这有2个好处:第一,强行补全视角;第二,把想清楚从一次性梭哈,变成逐步逼近,最终,让规划从黑盒直觉,变成可复盘的过程。
现在切换角色:你是一位非常挑剔的审稿专家/红队评审。目标:尽可能证伪你刚才的回答。要求:1)指出最脆弱的3个点(每个点都要具体,不要泛泛而谈)2)对每个点说明:你刚才隐含了什么假设?3)给出一个“会导致失败/结论反转”的场景或反例4)如果存在不确定性,请明确写出“不确定在哪里、需要什么信息才能确认”
unsetunset结语unsetunset
今天我们首先介绍了一个反认知提示词研究报告:最简单的操作反而能带来最显著的提升,提示词重复就可以大大提升模型回答质量!但紧接着我们也会发现,他依旧只能解决一点或者说一类问题。
与模型对话的本质,是在其架构限制下,通过设计来补偿理解与推理的不足。无论是重复提示、角色反转还是思维链,核心逻辑都是一致的:引导模型更充分、更结构化地“思考”。
而这一切只需要我们多试,面对实际问题的时候事实上也只有多试,我写起提示词也很蛋疼的...
。

责任编辑:
文章来源:http://www.jingmeijuzi.com/2026/0130/2065.shtml